
DirectSound3D A3D HRTF Обзор технологий позиционирования звука в пространстве
Обзор технологий позиционирования звука в пространстве
Звуковое сопровождение компьютера всегда находилось несколько на втором плане. Большинство пользователей более охотно потратят деньги на новейший акселератор 3D графики, нежели на новую звуковую карту.
Однако за последнее время производители звуковых чипов и разработчики технологий 3D звука приложили немало усилий, чтобы убедить пользователей и разработчиков приложений в том, что хороший 3D звук является неотъемлемой частью современного мультимедиа компьютера.
Пользователей убедить в пользе 3D звука несколько легче, чем разработчиков приложений. Достаточно расписать пользователю то, как источники звука будет располагаться в пространстве вокруг него, т.е. звук будет окружать слушателя сов всех сторон и динамично изменяться, как многие потянутся за кошельком. С разработчиками игр и приложений сложнее. Их надо убедить потратить время и средства на реализацию качественного звука. А если звуковых интерфейсов несколько, то перед разработчиком игры встает проблема выбора. Сегодня есть два основных звуковых интерфейса, это DirectSound3D от Microsoft и A3D от Aureal. При этом если разработчик приложения предпочтет A3D, то на всем аппаратном обеспечении DS3D будет воспроизводиться 3D позиционируемый звук, причем такой же, как если бы изначально использовался интерфейс DS3D. Само понятие "трехмерный звук" подразумевает, что источники звука располагаются в трехмерном пространстве вокруг слушателя. Это основа. Далее, что бы придать звуковой модели реализм и усилить восприятие звука слушателем, используются различные технологии, обеспечивающие воспроизведение реверберации, отраженных звуков, окклюзии (звук прошедший через препятствие), обструкции (звук не прошел через препятствие), дистанционное моделирование (вводится параметр удаленности источника звука от слушателя) и масса других интересных эффектов. Цель всего этого, создать у пользователя реальность звука и усилить впечатления от видео ряда в игре или приложении. Не секрет, что слух это второстепенное чувство человека, именно поэтому, каждый индивидуальный пользователь воспринимает звук по-своему. Никогда не будет однозначного мнения о звучании той или иной звуковой карты или эффективности той или иной технологии 3D звука. Сколько будет слушателей, столько будет мнений. В данной статье мы попытались собрать и обобщить информацию о принципах создания 3D звука, а также рассказать о текущем состоянии звуковой компьютерной индустрии и о перспективах развития. Мы уделим отдельное внимание необходимым составляющим хорошего восприятия и воспроизведения 3D звука, а также расскажем о некоторых перспективных разработках. Некоторые данные в статье рассчитаны на подготовленного пользователя, однако, никто не мешает пропустить нудные формулы тем, кому это не интересно или давно надоело в институте.
Итак, наверняка почти все слышали, что для позиционирования источников звука в виртуальном 3D пространстве используются HRTF функции. Ну что же, попробуем разобраться в том, что такое HRTF и действительно ли их использование так эффективно.
Сколько раз происходило следующее: команда, отвечающая за звук, только что закончила встраивание 3D звукового интерфейса на базе HRTF в новейшую игру; все комфортно расселись, готовясь услышать "звук окружающий вас со всех сторон" и "свист пуль над вашей головой"; запускается демо версия игры и… и ничего подобного вы просто не слышите!
HRTF (Head Related Transfer Function) это процесс посредством которого наши два уха определяют слышимое местоположение источника звука; наши голова и туловище являются в некоторой степени препятствием, задерживающим и фильтрующим звук, поэтому ухо, скрытое от источника звука головой воспринимает измененные звуковые сигналы, которые при "декодировании" мозгом интерпретируются соответствующим образом для правильного определения местоположения источника звука. Звук, улавливаемый нашим ухом, создает давление на барабанную перепонку. Для определения создаваемого звукового давления необходимо определить характеристику импульса сигнала от источника звука, попадающего на барабанную перепонку, т.е. силу, с которой звуковая волна отlисточника звука воздействует на барабанную перепонку. Эту зависимость называют Head Related Impulse Response (HRIR), а ее интегральное преобразование по Фурье называется HRTF.
Правильнее характеризовать акустические источники скоростью распространяемых ими звуковых волн V(t), нежели давлением P(t) распространяемой звуковой волны. Теоретически, давление, создаваемой идеальным точечным источником звука бесконечно, но ускорение распространяемой звуковой волны есть конечная величина. Если вы достаточно удалены от источника звука и если вы находитесь в состоянии "free field" (что означает, что в окружающей среде нет ничего кроме, источника звука и среды распространения звуковой волны), тогда давление "free field" (ff) на расстоянии "r" от источника звука определяется по формуле Pff(t) = Zo V(t - r/c) / r где Zo это постоянная называемая волновым сопротивлением среды (characteristic impedance of the medium), а "c" это скорость распространения звука в среде. Итак, давление ff пропорционально скорости в начальный период времени (происход "сдвиг" по времени, обусловленный конечной скоростью распространения сигнала. То есть возмущение в этой точке описывается скоростью источника в момент времени отстоящий на r/c - время которое затрачено на то, чтобы сигнал дошел до наблюдателя. В принципе не зная V(t) нельзя утверждать характера изменения скорости при сдвиге, т.е. произойдет замедление или ускорение) и давление уменьшается обратно пропорционально расстоянию от источника звука до пункта наблюдения. С точки зрения частоты давление звуковой волны можно выразить так: Pff(f) = Zo V(f) exp(- i 2 pi r/c) / r где "f" это частота в герцах (Hz), i = sqrt(-1), а V(f) получается в результате применения преобразования Фурье к скорости распространения звуковой волны V(t). Таким образом, задержки при распространении звуковой волны можно охарактеризовать "phase factor", т.е. фазовым коэффициентом exp(- i 2 pi r /c). Или, говоря словами, это означает, что функция преобразования в "free field" Pff(f) просто является результатом произведения масштабирующего коэффициента Zo, фазового коэффициента exp(- i 2 pi r /c) и обратно пропорциональна расстоянию 1/r. Заметим, что возможно более рационально использовать традиционную циклическую частоту, равную 2*pi*f чем просто частоту.
Если поместить в среду распространения звуковых волн человека, тогда звуковое поле вокруг человека искажается за счет дифракции (рассеивания или иначе говоря различие скоростей распространения волн разной длины), отражения и дисперсии (рассредоточения) при контакте человека со звуковыми волнами. Теперь все тот же источник звука будет создавать несколько другое давление звука P(t) на барабанную перепонку в ухе человека. С точки зрения частоты это давление обозначим как P(f). Теперь, P(f), как и Pff(f) также содержит фазовый коэффициент, чтобы учесть задержки при распространении звуковой волны и вновь давление ослабевает обратно пропорционально расстоянию. Для исключения этих концептуально незначимых эффектов HRTF функция H определяется как соотношение P(f) и Pff(f). Итак, строго говоря, H это функция, определяющая коэффициент умножения для значение давления звука, которое будет присутствовать в центре головы слушателя, если нет никаких объектов на пути распространения волны, в давление на барабанную перепонку в ухе слушателя.
Обратным преобразованием Фурье функции H(f) является функция H(t), представляющая собой HRIR (Head-Related Impulse Response). Таким образом, строго говоря, HRIR это коэффициент (он же есть отношение давлений, т.е. безразмерен; это просто удобный способ загнать в одну букву в формуле очень сложный параметр), который определяет воздействие на барабанную перепонку, когда звуковой импульс испускается источником звука, за исключением того, что мы сдвинули временную ось так, что t=0 соответствует времени, когда звуковая волна в "free field" достигнет центра головы слушателя. Также мы масштабировали результаты таким образом, что они не зависят от того, как далеко источник звука расположен от человека, относительно которого производятся все измерения.
Если пренебречь этим временным сдвигом и масштабированием расстояния до источника звука, то можно просто сказать, что HRIR - это давление воздействующее на барабанную перепонку, когда источник звука является импульсным.
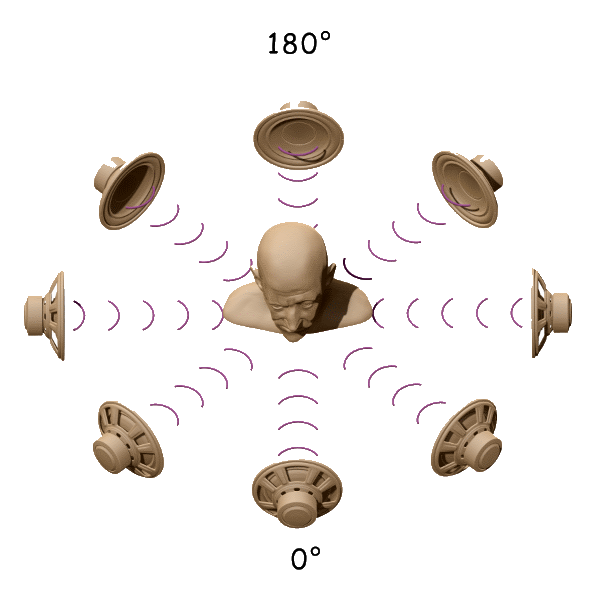
Напомним, что интегральным преобразованием Фурье функции HRIR является HRTF функция. Если известно значение HRTF для каждого уха, мы можем точно синтезировать бинауральные сигналы от монофонического источника звука (monaural sound source). Соответственно, для разного положения головы относительно источника звука задействуются разные HRTF фильтры. Библиотека HRTF фильтров создается в результате лабораторных измерений, производимых с использованием манекена, носящего название KEMAR (Knowles Electronics Manikin for Auditory Research, т.е. манекен Knowles Electronics для слуховых исследований) или с помощью специального "цифрового уха" (digital ear), разработанного в лаборатории Sensaura, располагаемого на голове манекена. Понятно, что измеряется именно HRIR, а значение HRTF получается путем преобразования Фурье. На голове манекена располагаются микрофоны, закрепленные в его ушах. Звуки воспроизводятся через акустические колонки, расположенные вокруг манекена и происходит запись того, что слышит каждое "ухо".
HRTF представляет собой необычайно сложную функцию с четырьмя переменными: три пространственных координаты и частота. При использовании сферических координат для определения расстояния до источников звука больших, чем один метр, считается, что источники звука находятся в дальнем поле (far field) и значение HRTF уменьшается обратно пропорционально расстоянию. Большинство измерений HRTF производится именно в дальнем поле, что существенным образом упрощает HRTF до функции азимута (azimuth), высоты (elevation) и частоты (frequency), т.е. происходит упрощение, за счет избавления от четвертой переменной. Затем при записи используются полученные значения измерений и в результате, при проигрывании звук (например, оркестра) воспроизводится с таким же пространственным расположением, как и при естественном прослушивании. Техника HRTF используется уже несколько десятков лет для обеспечения высокого качества стерео записей. Лучшие результаты получаются при прослушивании записей одним слушателем в наушниках.
Наушники, конечно, упрощают решение проблемы доставки одного звука к одному уху и другого звука к другому уху. Тем не менее, использование наушников имеет и недостатки Многие люди просто не любят использовать наушники. Даже легкие беспроводные наушники могут быть обременительны. Наушники, обеспечивающие наилучшую акустику, могут быть чрезвычайно неудобными при длительном прослушивании Наушники могут иметь провалы и пики в своих частотных характеристиках, которые соответствуют характеристикам ушной раковины. Если такого соответствия нет, то восприятие звука, источник которого находится в вертикальной плоскости, может быть ухудшено. Иначе говоря, мы будем слышать преимущественно только звук, источники которого находится в горизонтальной плоскости При прослушивании в наушниках, создается ощущение, что источник звука находится очень близко. И действительно, физический источник звука находится очень близко к уху, поэтому необходимая компенсация для избавления от акустических сигналов влияющих на определение местоположения физических источников звука зависит от расположения самих наушников.
Использование акустических колонок позволяет обойти большинство из этих проблем, но при этом не совсем понятно, как можно использовать колонки для воспроизведения бинаурального звука (т.е. звука, предназначенного для прослушивания в наушниках, когда часть сигнала предназначена для одного уха, а другая часть для другого уха). Как только мы подключим вместо наушников колонки, наше правое ухо начнет слышать не только звук, предназначенный для него, но и часть звука, предназначенную для левого уха. Одним из решений такой проблемы является использование техники cross-talk-cancelled stereo или transaural stereo, чаще называемой просто алгоритм crosstalk cancellation (для краткости CC). Идея CC просто выражается в терминах частот. Сигнал Y1 достигающий левого уха представляет собой смесь из S1 и "crosstalk" (части) сигнала S2. Чтобы быть более точными, Y1=H11 S1 + H12 S2, где H11 является HRTF между левой колонкой и левым ухом, а H12 это HRTF между правой колонкой и левым ухом. Аналогично Y2=H21 S1 + H22 S2. Если мы решим использовать наушники, то мы явно будем знать искомые сигналы Y1 и Y2 воспринимаемые ушами. Проблема в том, что необходимо правильно определить сигналы S1 и S2, чтобы получить искомый результат. Математически для этого просто надо обратить уравнение При очень низкой частоте звука, все функции HRTF одинаковы и поэтому матрица является вырожденной, т.е. матрицей с нулевым детерминантом (это единственная помеха для тривиального обращения любой квадратной матрицы). На западе такие матрицы называют сингулярными. (К счастью, в среде отражающей звук, т.е. где присутствует реверберация, низкочастотная информация не являются важной для определения местоположения источника звука Точное решение стремиться к результату с очень длинными импульсными характеристиками. Эта проблема становится все более и более сложной, если в дальнейшем искомый источник звука располагается вне линии между двумя колонками, т.е. так называемый фантомный источник звука Результат будет зависеть от того, где находится слушатель по отношению к колонкам. Правильное восприятие звучания достигается только в районе так называемого "sweet spot", предполагаемого месторасположения слушателя при обращении уравнения. Поэтому, то, как мы слышим звук, зависит не только от того, как была сделана запись, но и от того, из какого места между колонками мы слушаем звук.
При грамотном использовании алгоритмов CC получаются весьма хорошие результаты, обеспечивающие воспроизведение звука, источники которого расположены в вертикальной и горизонтальной плоскости. Фантомный источник звука может располагаться далеко вне пределов линейного сегмента между двумя колонками. Давно известно, что для создания убедительного 3D звучания достаточно двух звуковых каналов. Главное это воссоздать давление звука на барабанные перепонки в левом и правом ушах таким же, как если бы слушатель находился в реальной звуковой среде. Из-за того, что расчет HRTF функций сложная задача, во многих системах пространственного звука (spatial audio systems) разработчики полагаются на использование данных, полученных экспериментальным путем, например, данные получаются с помощью KEMAR. Тем не менее, основной причиной использования HRTF является желание воспроизвести эффект elevation (звук в вертикальной плоскости), наряду с азимутальными звуковыми эффектами. При этом восприятие звуковых сигналов, источники которых расположены в вертикальной плоскости, чрезвычайно чувствительно к особенностям каждого конкретного слушателя. В результате сложились четыре различных метода расчета HRTF Использование компромиссных, стандартных HRTF функций. Такой метод обеспечивает посредственные результаты при воспроизведении эффектов elevation для некоторого процента слушателей, но это самый распространенный метод в недорогих системах. На сегодня, ни IEEE, ни ACM, ни AES не определили стандарт на HRTF, но похоже, что компании типа Microsoft и Intel создадут стандарт де-факто
Использование одной типа HRTF функций из набора стандартных функций. В этом случае необходимо определить HRTF для небольшого числа людей, которые представляют все различные типы слушателей, и предоставить пользователю простой способ выбрать именно тот набор HRTF функций, который наилучшим образом соответствует ему (имеются в виду рост, форма головы, расположение ушей и т.д.). Несмотря на то, что такой метод предложен, пока никаких стандартных наборов HRTF функций не существует использование индивидуализированных HRTF функций. В этом случае необходимо производить определение HRTF исходя из параметров конкретного слушателя, что само по себе сложная и требующая массы времени процедура. Тем не менее, эта процедура обеспечивает наилучшие результаты Использование метода моделирования параметров определяющих HRTF, которые могут быть адаптированы к каждому конкретному слушателю. Именно этот метод сейчас применяется повсеместно в технологиях 3D звука.