
Основной принцип активного декодирования - усиление по доминантному направлению
Основной принцип активного декодирования - усиление по доминантному направлению
Как известно, пассивные декодеры используют простую разностную схему для извлечения компоненты Surround из входных сигналов Lt и Rt. Т.е. эта компонента сильно отличается от того, что было 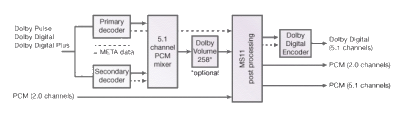 заложено в программу при Dolby- кодировании. Ведь разница между Lt и Rt определяется не только наложением на них противофазных составляющих Surround, но и, собственно, их входными различиями. Т.е. нельзя говорить о полной независимости фронтальных и Surround каналов.
заложено в программу при Dolby- кодировании. Ведь разница между Lt и Rt определяется не только наложением на них противофазных составляющих Surround, но и, собственно, их входными различиями. Т.е. нельзя говорить о полной независимости фронтальных и Surround каналов.
Кроме того, пассивные декодеры создают качественную звуковую картину только для зрителей, которые сидят в четко определенном месте - где хорошо слышен центральный Phantom-динамик.
"Усиление по доминантному направлению" это термин, который применяется к любому методу ослабления эффекта смешения выходных сигналов пассивной матрицы путем манипулирования ее выходными. Целью таких методов является создание остросфокусированных звуковых образов доступных для восприятия в широкой зоне прослушивания. Активный декодер - в самом общем смысле, это пассивный декодер дополненный цепью выборочного усиления. Существует несколько довольно распространенных схем. Они все используют многоканальные выходные усилители, управляемые напряжением. В некоторых случаях декодеры дополняются системами вычитания из фронтальных сигналов центральных и Surround каналов (так называемая "концепция аннулирования"). Но самыми распространенными активными декодерами сегодня являются декодеры, использующие так называемую "концепцию постоянного общего уровня".
Источник:
Источник:
Применение пассивных декодеров не способно обеспечить правильную локализацию источников звука в пространстве на значительной площади прослушивания. С этой точки зрения определенным преимуществом обладают декодеры с регулируемым усилением в канале воспроизведения, точно также как это выполняется в адаптивных стереофонических системах звукопередачи. Возможны два подхода к их построению. Предположим, что каждый из выходных каналов содержит свой усилитель УУ1----УУ4 с управляемым коэффициентом передачи. Пусть сигналы управления для них суммируются из входных сигналов ДКУ L1, R1, а также из их суммы L1 + R1 и разности L1 – R1 в специальном блоке БФУС. В этом блоке определяется, в каком канале следует уменьшить усиление, чтобы ослабить (подавить) мешающие (вредные) сигналы. Например, если на входе КУ присутствует только сигнал С, то следует уменьшить усиление в каналах L и R и т.п. Фактически звук может приходить с любого направления в пределах 360° и этого можно достичь, меняя в соотношение уровней сигналов в каналах воспроизведения. Но нужно это делать таким образом, чтобы для любого направления формирование КИЗ выполнялось бы сигналами не более чем двух каналов воспроизведения, точно также как это делается, например, в режиме формирования единственного КИЗ стереофонической системы повышенного качества звучания. Однако таким методом задача решается эффективно, лишь для случая единственного КИЗ. Ситуация существенно усложняется, если звуковых образов несколько. Пусть, например, речь звучит на фоне музыки, при этом музыка по замыслу оператора должна воспроизводится громкоговорителями каналов L и R, а речь — громкоговорителем канала С. Пассивный декодер с этой задачей вообще не справится: речь будет воспроизводиться громкоговорителями всех трех каналов L, С, R; через громкоговоритель канала С будет прослушиваться и суммарный сигнал L + R, а через громкоговоритель канала S — разностный сигнал L — R. Теперь предположим, что ДКУ считает доминирующим сигналом речь, тогда он должен увеличить уровень сигнала в канале С и уменьшить соответственно уровень сигнала в каналах L и R. При этом музыкальное сопровождение останется в каналах С (монофонический сигнал L + R) и S (разностный сигнал L — К). В моменты времени, когда говорящие герои замолкают (пауза), восстанавливается усиление в каналах L и R. При появлении речи музыкальное сопровождение по уровню опять уменьшается. Такие изменение в звучании легко ощутимы, заметны на слух. Другой способ состоит в попытке компенсации мешающих сигналов путем формирования их противофазных компонент и последующего сложения с исходными сигналами. Например, если взять сигнал правого канала R и инвертировать его по фазе и затем сложить с выходным сигналом левого канала L, то компоненты сигнала С в левом и правом каналах окажутся противофазными и после сложения взаимно компенсируются, а значит в канал L компоненты сигнала С не попадут. Именно этот принцип взаимной компенсации (cancellation concept) и используется в активных декодерах системы Dolby Pro Logic. Важно, что после исключения компонент сигнала С из левого канала воспроизведения, громкость (энергия сигнала) звука в этом канале не упадет, ибо компоненты сигнала С заместятся в этом канале инвертированным сигналом канала R (constant — power concept). В центральном канале по-прежнему прослушивается также и сумма сигналов L + R. В итоге доминирующий сигнал речи (фокусируется) в направлении громкоговорителя центрального канала С, а музыкальный фон, по-прежнему воспроизводится громкоговорителями каналов L и R и воспринимается как размытый звуковой образ. Здесь используется важное свойство психологии слуха — его способность концентрировать внимание именно на доминантном направлении, воспринимая все остальные звуки с других направлений как размытый (без четкой идентификации его в пространстве) звуковой образ. Этот принцип получил название «выделение доминирующего направления». Рассматривая этот пример, мы предполагали, что громкость речи существенно выше музыкального фона. Если оба сигнала по уровню громкости близки, то один из них становится маскирующим для компонентов другого, попавшего не в свои каналы и требования к их «развязке» снижаются. В некоторых ситуациях вообще желательно исключить регулировку уровней сигналов на выходах ДКУ, сделав декодер пассивным. Этот режим аналогичен режиму множества КИЗ в системах с адаптацией. Например, звуки дождя или ветра. Они не связываются с каким либо конкретным каналом и могут воспроизводиться всеми громкоговорителями. Самая крайняя ситуация — все звуки связаны с одним единственным направлением (единственный КИЗ). С этой ситуацией не может справиться пассивный декодер, но для активного декодера — это наиболее простая ситуация. Самая трудная ситуация, когда мы должны передать одновременно два разных направления без доминирования. В такой системе, которая постоянно перестраивается, выделяя то или иное доминирующее направления звука, очень важную роль играет с позиций слуха оптимальный выбор временных параметров декодера. Здесь также реализовано два режима работы — быстрый и медленный. Быстрый режим реакции ДКУ используется, если доминирующее направление явно выражено и если эти направления последовательно меняются. Медленный режим используется, когда доминирующих направлений несколько и они близки по уровню громкости. Вся информация, необходимая активному декодеру для управления усилением каналов воспроизведения извлекается им из входных сигналов. Ее достаточно для идентификации любого направления, что иллюстрирует рисунок 4. Здесь ось X соответствует левому L и правому R направлениям звука (каналы L и R), ось Y — фронтальному (канал С) и тыловому направлениям (канал S) локализации. Меняя амплитуды каждого из этих четырех выходных сигналов можно получить любое направление локализации звука в горизонтальной плоскости.